Here at CBUSDAW, we’ve been lucky to have some sponsors come back for multiple years. This kind of steadfast support is a big part of what has allowed us to keep at this for so long (18 years and counting!). Each month at the beginning of the event, that month’s emcee (typically Tim or Bryan) reads off a short description of each sponsor. Something like this:
Conductrics: A decision optimization platform that uses machine learning and AI to enable businesses to personalize and optimize their customers’ experiences.
As far as a short description of what Conductrics does, that sounds fine. But what does that really mean? What does Conductrics really do?
After having Conductrics as a sponsor for a number of years, we decided it was time to dig a little deeper. Last year we did something similar for Piwik PRO, and this year it’s Conductrics’ turn. Conductrics has been a generous sponsor not just of CBUSDAW, but many other great analytics and testing events including Experimentation Island, Superweek and MeasureCamps around the world (Austin, Helsinki, Stockholm, North America, London, and more).
If you’ve been to one of those events and seen Conductrics’ CEO Matt Gershoff speak — you got some serious knowledge dropped on you, but something that was as far away from a product pitch as you can possibly imagine a CEO giving. In Columbus for our August 2024 event, Matt gave an insightful talk about intentionality in data collection and privacy by design in which there were a lot more slides featuring his dog Franklin (I counted 9) than screenshots from his product (2).
So what’s unique about Conductrics? Let’s start by unpacking that monthly blurb a bit:
“Decision optimization platform” – Conductrics is an A/B testing platform, but it can do a lot more than just running basic A/B tests. It also does surveys, it does predictive targeting of variations, it allows for comprehensive rules-based targeting for variations, and it connects all of those different pieces of functionality together into a cohesive platform.
“that uses machine learning and AI” – When Conductrics says “machine learning and AI”, they mean that they are using algorithms to help with things like predictive targeting. There’s not a bunch of ✨ icons in the application to generate slop variations or anything along those lines (in fact there are no ✨ icons in the app at all that I saw).
“to enable businesses to personalize and optimize their customers’ experiences” – It’s a customer experience optimization platform for sure, and I think it’s helpful to highlight the “customer” part of that equation. Conductrics is designed to plug into the overall customer experience, which represents a more holistic way to think about CX optimization. This means thinking beyond how to get more clicks on your checkout button and how to improve the entire customer experience. In 2026 “the customer experience” also means a lot more than a webpage, it means everything from mobile apps to API endpoints accessed via agentic AI. If the experience delivery mechanism can be hooked in to an API, it can be included in the personalization and optimization capabilities of the platform.
The red-button / blue-button approach to testing is outdated, but the mindset lingers
Among the CBUSDAW organizers, we don’t have a ton of expertise in modern testing and experimentation practices. Or if we do someone should have spoken up more loudly in the group chat, because you’re stuck with me (Jason) writing this — who is not an expert. I still think about how A/B (or multivariate) testing worked in Google Optimize (sunset in 2023), and even back to the heady days of freemium Optimizely plans. Conventional wisdom from those days was:
- Test a lot of variations on pages that directly impact conversion: landing pages, checkout pages, etc.
- Whatever variation the tool says impacted conversion most wins.
- Rinse and repeat.
This approach isn’t wrong, but it’s very limiting.
In my experience, often this also focuses on small changes repeatedly applied to the same conversion. For example, trying to repeatedly and randomly optimize the same add-to-cart button. This has a low ceiling of effectiveness, as it typically focuses only on things that are very directly related to the conversion, are typically design & content related (rather than functionality), and apply across all customer segments.
Good experimentation should start with a hypothesis, not “let’s test every possible color for the checkout button and see what scores best”. That’s effectively a form of p-hacking, not a coherent practice. Without a hypothesis, people back into a theory to explain whatever “winner” emerges.
Sometimes those winners really are improvements, but sometimes there are other uncontrolled changes or confounds going on, or even just randomness.
This can be a resource-waster for many sites, especially low volume sites where a statistically significant winner could take some time to discover. This led a number of smaller organizations that I worked with to simply abandon A/B testing. If you don’t commit to a robust testing practice, you’re likely to get weak results.
Impactful testing requires context
Thinking about tests as being self-contained is one of the biggest weaknesses of this older approach.
Let’s say you ran a test of your cart checkout page with an updated design that you were really excited about. But the experiment showed it actually performed worse than the existing design!
Without deeper context about your customers, you would have to assume the new design was worse. Yet perhaps the real answer was that many customers who saw the test were returning customers who were confused by the new design and put off checking out with their regular order. Maybe the new customers loved it and checked out at a much higher rate, but without segmentation you’d never know that.
Using a more advanced testing platform, you could have shown the new design to new customers only, or shown the new design to a small % of return customers and included a short survey asking for existing customers to rate the new design.
This approach can help you understand your best customers and maybe do more follow-up testing. Do existing customers need time to adjust to the new checkout? Or perhaps new customers are checking out with only 1 or 2 items and those return customers have big orders where the checkout doesn’t work as well? Maybe you even need different checkouts for repeating vs one-time customers? Without a deeper context and integration, your testing is ultimately much more superficial.
Product testing requires even deeper integration
An advanced experimentation practice means testing more than just content. You can test landing pages all day, but if the product they are marketing sucks then what’s the point? Your analytics might tell you customers don’t like your checkout or your site search, but you can’t just pop variations of those into your front-end testing tool via your tag manager. Testing functionality requires integrating your testing platform deeper into the product, into the code and logic of the product itself and not just the front-end.
This is where server-side testing comes in. Not only does Conductrics support this, but in fact Conductrics started as a server-side testing tool. It supports client-side as well now, but this kind of deeper integration remains at the heart of the platform. When you create any kind of test or experience, you can deploy that test to any number of targets, either automatically or manually.
Let’s say you wanted to test new search results, you might deploy that test to your iOS & Android App and a server-side API used by your web app (but not your Google Tag Manager). Conductrics is designed for these kinds of scenarios:
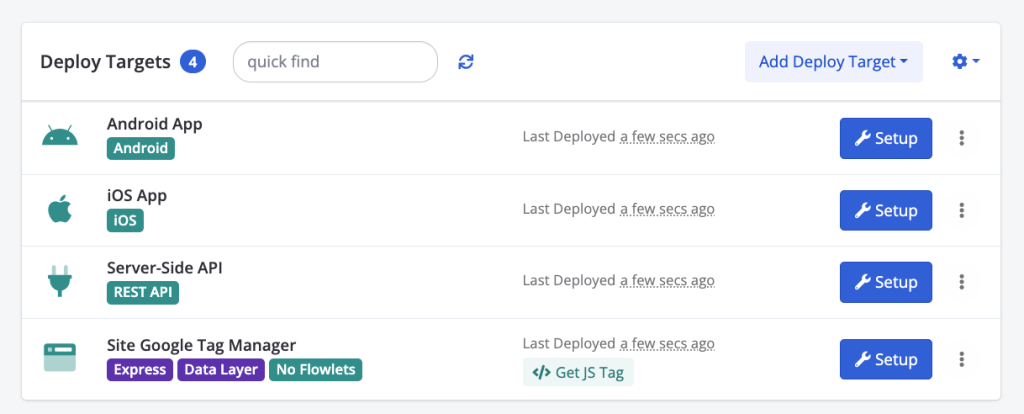
These sorts of advanced features are both what makes Conductrics so powerful, and also shows why this is an enterprise product designed for organizations with more complex needs. If you’re just wanting to run client-side A/B testing, this would be overkill.
The math matters
Most of us aren’t stats experts. We don’t know the difference between a Welch’s vs. Student t-test, and when we see something like “the CUPED variance reduction formula: Var(Y_ra) = Var(Y) * (1 – Cor(Y, Covariate)2)” we probably just skip over that part and keep reading. You just did that yourself right now, didn’t you?
I’m not saying you need to take a stats class before you start a testing practice, but I do think that there’s a big pitfall many organizations hit by completely ignoring the math and treating it as a black box.
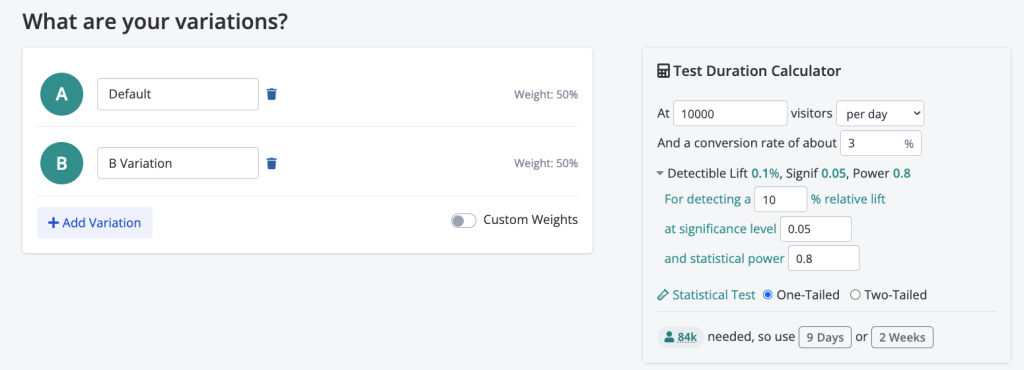
When we just look at who won a test and let our testing platform have full control over the statistical parameters of a test we greatly increase the risk of running bad tests that lead us astray.
Conductrics puts you closer to the math. When you start an A/B test, they’ve chosen to place a calculator right on the page. It’s got sensible defaults so you don’t have to delve into these details, but it’s bringing it to the foreground.
Playing well with others
One of the most frustrating things about digital marketing tools like Google or Adobe is that they don’t integrate well with other platforms. For example, the increase in agentic AI has recently led to more people talking about data layers and semantic layers. I’ve long found data layers to be one of the most useful ways to pass data between different digital marketing tools. Yet everyone has their own competing standard: Google has “dataLayer” (yes, they called their data layer standard “data layer”), Adobe has Adobe Client Data Layer, Tealium has Universal Data Object, etc. GA/GTM’s ubiquity has led to their dataLayer being the closest thing we have to a universal standard, but it is far from universal and there is even less standardization of the contents of data layers. This chaos is repeating itself with competing semantic layer standards.

When discussing competing standards, it’s required to include this XKCD comic.
Conductrics recognizes that we live in a world with all these competing standards. In order to offer the level of integration that I’ve touted as being necessary for a next-level experimentation program, you need to be able to plug into anything. Here’s an example of the data layer configuration options in Conductrics:
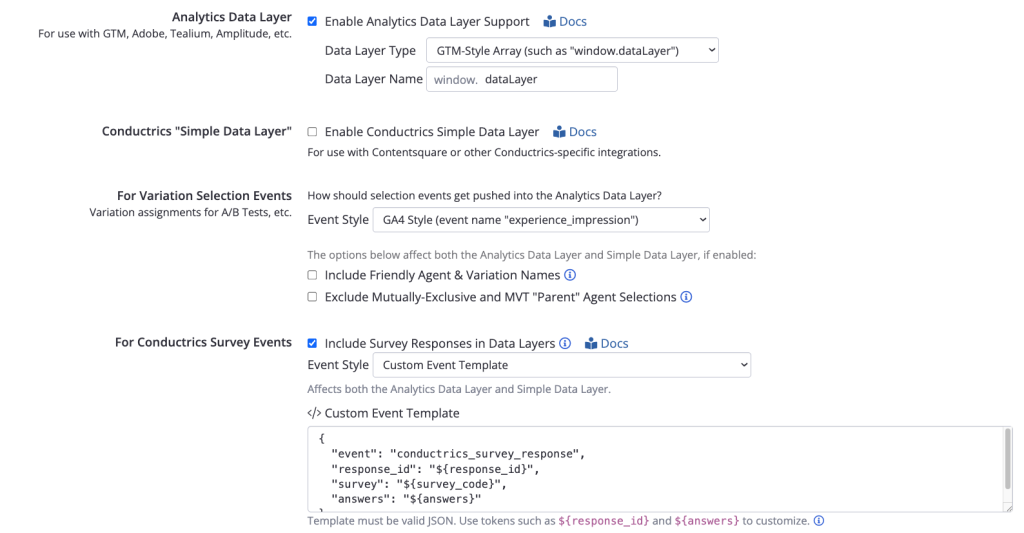
If you want to do Google-style dataLayer, you can do that. Or if you’re using Tealium and their weird flat uTag object you can do that instead! A data layer allows you to plug into anything, but Conductrics is going above-and-beyond here to give you options on different data layer standards and events to make these integrations easier.
If I’ve lost you with this data layer stuff and these screen shots seem too complicated, I get that. But trust me that your GTM, Adobe Launch, or Tealium implementation folks are going to appreciate this. This is illustrative again of how Conductrics is more of a specialists’ platform and probably not what you’re looking for if you want to run your first A/B test for a small or medium business.
Final Words
There are a lot of tools out there in the testing space, and we’re not here to sell you on Conductrics vs. Optimizely/Adobe/AB Tasty/etc. If you just want to run some simple surveys or some basic A/B content testing then you may in fact be better served by tools like VWO, Convert.com, or more likely even the A/B testing built into your primary marketing content platform like HubSpot, Unbounce, Klaviyo, etc.
Our goal with this article is to help members of our analytics community better understand our long-time sponsor Conductrics and what kind of platform they are. As always, we avoid sales pitches at our events and try to focus on concepts that apply to all vendors, so we wanted to take this opportunity to talk about tool specifics in a long-form post.
If you’re interested in learning more, book a demo with Conductrics here.